Analysis
36 - National Ridership Growth (2019 vs 2024)
Equity and Strategic Planning
Coverage: 2002-01 to 2025-12 (from ntd_ridership).
Built 2026-06-15 11:52 UTC · Commit e5cf673
Page Navigation
Analysis Navigation
Data Provenance
flowchart LR
36_national_ridership_growth(["36 - National Ridership Growth (2019 vs 2024)"])
t_ntd_agency[("ntd_agency")] --> 36_national_ridership_growth
05_ntd_ridership[["NTD Ridership ETL"]] --> t_ntd_agency
u1_05_ntd_ridership[/"data/ntd-monthly-ridership/December 2025 Complete Monthly Ridership (with adjustments and estimates)_260202.xlsx"/] --> 05_ntd_ridership
t_ntd_ridership[("ntd_ridership")] --> 36_national_ridership_growth
05_ntd_ridership[["NTD Ridership ETL"]] --> t_ntd_ridership
d1_36_national_ridership_growth(("polars (lib)")) --> 36_national_ridership_growth
classDef page fill:#dbeafe,stroke:#1d4ed8,color:#1e3a8a,stroke-width:2px;
classDef table fill:#ecfeff,stroke:#0e7490,color:#164e63;
classDef dep fill:#fff7ed,stroke:#c2410c,color:#7c2d12,stroke-dasharray: 4 2;
classDef file fill:#eef2ff,stroke:#6366f1,color:#3730a3;
classDef api fill:#f0fdf4,stroke:#16a34a,color:#14532d;
classDef pipeline fill:#f5f3ff,stroke:#7c3aed,color:#4c1d95;
class 36_national_ridership_growth page;
class t_ntd_agency,t_ntd_ridership table;
class d1_36_national_ridership_growth dep;
class u1_05_ntd_ridership file;
class 05_ntd_ridership pipeline;
Findings
Findings: National Ridership Growth (2019 vs 2024)
Summary
Among the 150 largest US transit agencies, the median ridership change from 2019 to 2024 was −22.4%. Only 11 of 150 agencies (7%) recovered to pre-pandemic levels. PRT ranks 136th out of 150, with a −42.4% decline.
Key Numbers
- Median change: −22.4%
- Mean change: −22.4%
- IQR: −33.4% to −12.0%
- Agencies recovered to 2019 levels: 11 / 150 (7%)
- PRT rank: 136 / 150 (−42.4% change)
- PRT 2019 UPT: 64.1 million → 2024 UPT: 36.9 million
- Top recovery: City of Alexandria (+34.6%)
- Bottom: Puerto Rico Highway and Transportation Authority (−85.8%)
Observations
- The transit industry as a whole has not recovered to 2019 ridership levels. The median agency is still down about one-fifth.
- Only a handful of mostly smaller or mid-size agencies — Alexandria, Richmond, Tucson, Albany — have grown past their 2019 totals, often reflecting route restructures or fare-free programs.
- Large legacy systems (BART −56%, Metrolink −60%) lag due to heavy reliance on commuter/office workers who shifted to remote work.
- PRT's −42.4% decline places it in the bottom quintile, substantially below the median. This is worse than most similarly-sized agencies.
- The distribution is roughly normal around −22%, with a long left tail of commuter-heavy agencies.
Discussion
PRT's below-median recovery suggests Pittsburgh-specific headwinds beyond the national pandemic trend. Possible factors include sustained remote-work adoption in major employers (UPMC, university sector), service cuts that may have dampened demand, and light rail losses that drag the overall figure below bus-only recovery.
Caveats
- "Top 150" is defined by 2019 UPT, which excludes agencies that have grown from a small base.
- Requires at least 10 months of data per year to exclude partial-year artifacts; a few agencies near the cutoff may have slightly biased totals.
- UPT counts all modes and TOS combined; agencies with large commuter rail components (which recovered less) appear worse than bus-only peers.
- NTD data includes estimates and adjustments; some months may be revised after initial reporting.
Output
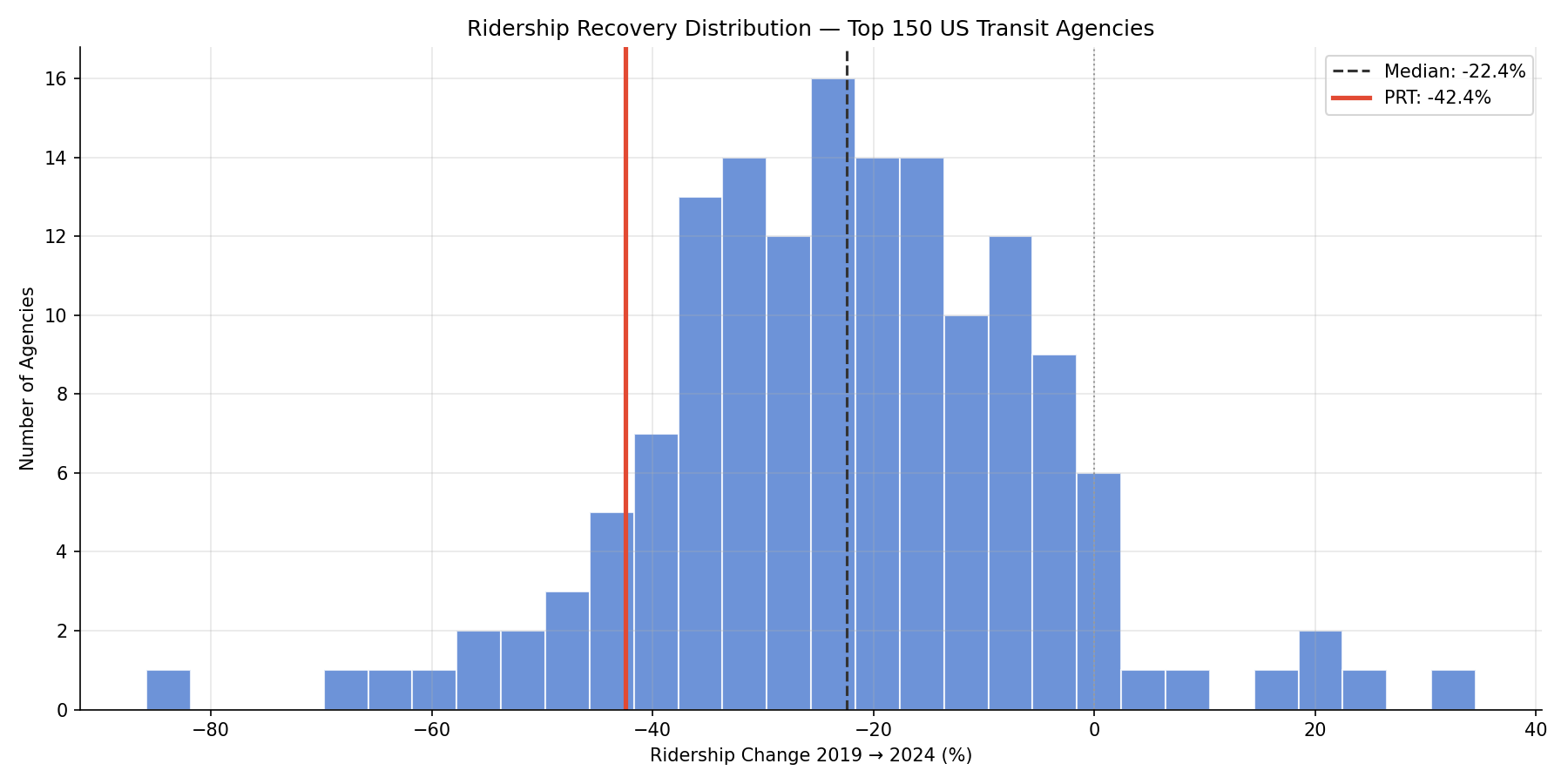
histogram of percent change with PRT highlighted.
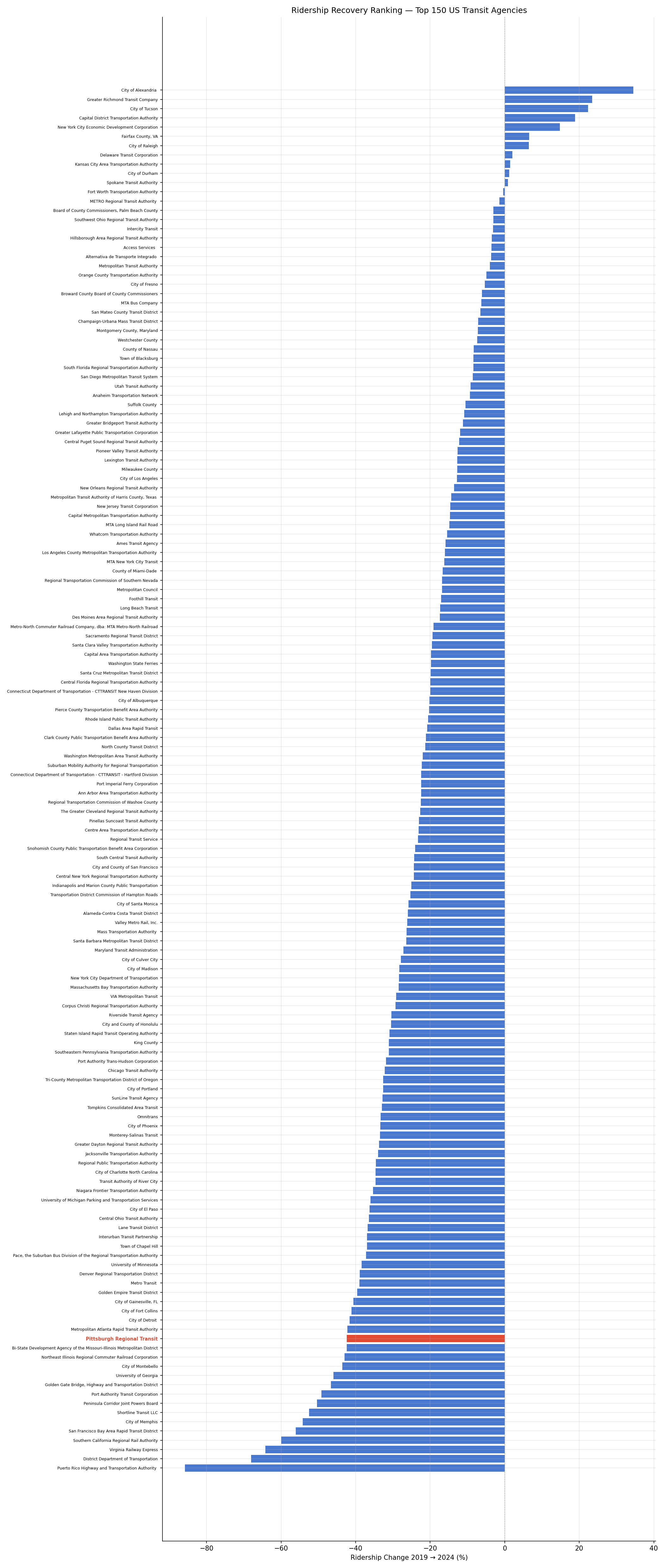
horizontal bar chart of all 150 agencies, PRT in distinct color.
No interactive outputs declared.
per-agency data (ntd_id, agency_name, upt_2019, upt_2024, pct_change, rank).
Preview CSV
Methods
Methods: National Ridership Growth (2019 vs 2024)
Question
What is the average 2019-to-2024 ridership change across the 150 largest US transit agencies, and where does Pittsburgh Regional Transit rank?
Approach
- Sum unlinked passenger trips (UPT) by agency across all modes/TOS for calendar years 2019 and 2024.
- Require at least 10 months of non-null data in both years to avoid partial-year artifacts.
- Rank agencies by 2019 total to define the "top 150" (pre-pandemic baseline, not distorted by COVID).
- Compute percent change ((2024 − 2019) / 2019 × 100) per agency.
- Report median, mean, and IQR of the percent change distribution.
- Count how many agencies have recovered to or exceeded 2019 levels.
- Identify PRT's rank in the distribution.
Data
ntd_ridership— monthly UPT by agency/mode/TOS, filtered to 2019 and 2024.ntd_agency— agency names for labeling.
Output
output/ridership_growth_distribution.png— histogram of percent change with PRT highlighted.output/ridership_growth_ranking.png— horizontal bar chart of all 150 agencies, PRT in distinct color.output/ridership_growth_data.csv— per-agency data (ntd_id, agency_name, upt_2019, upt_2024, pct_change, rank).
Source Code
|
Sources
| Name | Type | Why It Matters | Owner | Freshness | Caveat |
|---|---|---|---|---|---|
| ntd_agency | table | Primary analytical table used in this page's computations. | Produced by NTD Ridership ETL. | Updated when the producing pipeline step is rerun. | Coverage depends on upstream source availability and ETL assumptions. |
Upstream sources (1)
|
|||||
| ntd_ridership | table | Primary analytical table used in this page's computations. | Produced by NTD Ridership ETL. | Updated when the producing pipeline step is rerun. | Coverage depends on upstream source availability and ETL assumptions. |
Upstream sources (1)
|
|||||
| polars | dependency | Runtime dependency required for this page's pipeline or analysis code. | Open-source Python ecosystem maintainers. | Version pinned by project environment until dependency updates are applied. | Library updates may change behavior or defaults. |